1.5. Ricerca sui file: find, locate, grep
1.5.1. find
Per poter individuare un file presente in qualche dispositivo di memorizzazione (sia floppy disk, hard disk, CD-ROM, etc) senza conoscere adeguatamente il percorso si possono impiegare diversi strumenti a propria scelta; il comando comunque base Ë find (trova). Questa Ë una sintassi semplificata su come si possono richiedere le sue funzioni:
find [percorso...] -iname modello
[percorso...] significa che Ë possibile inserire un singolo o pi˘ indicazioni di percorsi, di punti da cui fare partire la ricerca. Se si mettesse / allora cercher‡ ovunque, in tutti i dispositivi attivi. Si puÚ iniziare con / e aggiungere directory per delimitare solo in alcune zone la ricerca. Oppure puÚ essere un parametro non indicato (nella sintassi Ë fra parentesi quadre, cioË parametro opzionale), in questo modo la ricerca verr‡ limitata alla directory corrente.
# find /usr/X11R6/ /home/ -iname .fvwm2rc |
Per modello intende i caratteri che compongono la parola da cercare, con la possibilit‡ di usare caratteri speciali come l'asterisco (*), facilitazione che permette di tralasciare di specificare ogni carattere dei file a cui si sta puntando.
Ad esempio nel caso si dovesse individuare la posizione del documento Sound-HOWTO, in un formato qualsiasi, si ignora se sia nel proprio hard disk oppure nel CD-ROM inserito, si potrebbe impostare la ricerca come nell'Esempio 1-4.
Nell'Esempio 1-5 find trover‡ le occorrenze pj98* e pj99*, ossia tutti i numeri relativi all'anno 1999 e 1998 di una rivista. Sono utilizzati i caratteri speciali [ e ], che identificano l'elenco dei caratteri che possono essere presenti in una sola posizione in un modello (pattern). Per una spiegazione estesa su questo tipo di caratteri speciali si rimanda al capitolo Modelli di occorrenza (o pattern matching).
1.5.2. locate
locate (localizza) Ë un programma che d‡ la possibilit‡ di svolgere una ricerca di file come find ma con velocit‡ molto diversa. La differenza Ë nel fatto che locate basa la sua ricerca su un elenco dei file presenti raccolto in precedenza, non va direttamente a vedere cosa si trova nei percorsi indicati, con un risparmio di tempo incomparabile.
Per un conveniente uso, comunque, bisogna avere aggiornato questo elenco dei file. Il sistema operativo puÚ essere configurato per farlo in maniera automatica entro un periodo di tempo (ad esempio ogni settimana, ogni tre giorni). Se l'impostazione predefinita della propria distribuzione non Ë efficiente, puÚ essere fatto manualmente tramite il il comando updatedb.
L'uso di locate Ë perÚ diverso da find nell'impostare lo schema di ricerca dato che non fa riferimento solo sui nomi di file ma su tutto il percorso, inoltre nei casi pi˘ semplici non Ë necessario porre asterischi.
# locate bzip2 /usr/bin/bzip2 /usr/bin/bzip2recover /usr/man/man1/bzip2.1.gz |
Per specificare di ignorare le differenze fra caratteri maiuscoli e minuscoli si puÚ usare l'opzione --ignore-case (o, abbreviato, -i). Nell'esempio si cercher‡ per directory e nomi di file che iniziano con Bzip e bzip, l'opzione ha permesso che vengano scovati documenti come Bzip2.html, altrimenti ignorati.
# locate -i */bzip* /usr/bin/bzip2 /usr/bin/bzip2recover /usr/doc/ildp/HOWTO/mini/Bzip2.html /usr/doc/ldp/howto/html/mini/Bzip2-1.html [...] /usr/doc/bzip /usr/doc/bzip/LICENSE /usr/doc/bzip/manual_1.html /usr/doc/bzip/manual_2.html [...] /usr/doc/bzip/manual_toc.html /usr/doc/bzip/README |
1.5.3. grep
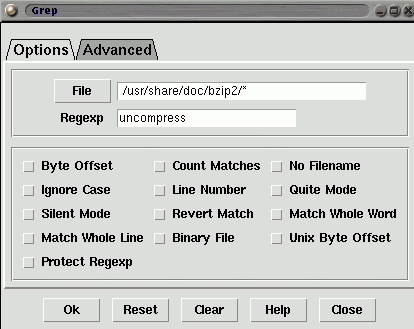
grep (global regular expression printer; visualizzatore di espressioni regolari globali) Ë uno stimato programma che permette di compiere una ricerca all'interno dei file evitando di visualizzare tutto il contenuto. Mostrer‡ ogni riga che contiene parole che rispettano il modello (pattern) che viene indicato. Opzionalmente si puÚ ottenere la visualizzazione insieme alla riga con il modello, di una o pi˘ adiacenti ad essa.
La sintassi essenziale proposta Ë questa:
grep [-i] [-r] modello file...
programma | grep [-i] [-r] modello
Esempio 1-6. grep, ricerca di una parola e selezione di file tramite carattere speciale
/usr/doc/programmi/xf86 # grep -r dpms ./ ./README.apm:"standby", "suspend" and "off" modes (set with the "xset dpms" command). |
L'Esempio 1-6 mostrer‡ solo la riga in cui Ë presente la parola "dpms" e indicher‡ i nomi dei file che contengono la relativa occorrenza fra tutti quelli presenti a partire dalla directory corrente (indicata con ./).
L'informazione che si cercava, qualche indicazione su come impostare le modalit‡ a basso consumo del monitor (le specifiche DPMS), in tal caso sono subito fornite perchÈ insieme al file README.apm, che la contiene, viene indicata proprio la riga che fornisce il comando base impiegabile allo scopo (xset).
L'opzione -r, o, estensivamente --recursive, dice a grep di addentrarsi nelle eventuali directory che incontra nel percorso di ricerca.
» utile sapere come fare ignorare le differenze fra maiuscole e minuscole, questo lo si ottiene con l'aggiunta dell'opzione -i (o --ignore-case), carattere la i che vale tra l'altro anche per -iname di find.
Nel successivo esempio si visualizzano parti del riepilogo delle opzioni di grep, solo le righe in cui Ë presente la parola righe risulteranno.
# grep --help | grep righe -x, --line-regexp forza MODELLO a corrispondere solo a righe intere -v, --invert-match seleziona le righe che non corrispondono -b, --byte-offset stampa l'offset del byte con le righe di output -n, --line-number stampa il numero della riga con le righe di output -c, --count stampa solo il conto delle righe occorrenti in ogni FILE -B, --before-context=NUM stampa NUM righe di contesto precedente -A, --after-context=NUM stampa NUM righe di contesto seguente -C, --context[=NUM] stampa NUM righe (2 predefinite) di contesto |
Per le informazioni sulle regole circa la definizione dei modelli si rimanda al Capitolo 2.
Fra le varianti del comando si segnalano zgrep, una estensione che Ë in grado di cercare all'interno di file compressi che hanno estensione .gz o .Z, bzgrep per i file compressi con bzip2, zipgrep per i file compressi .zip.
1.5.4. Programmi alternativi all'uso di grep e find
- Midnight Commander
Home page: Requisiti: Nessuno, o X-Window in versione gmc; (Mouse opzionale, con [F9] si accede al menu via tastiera) Molto diffuso gestore di file (file manager). Per avere un interfaccia pi˘ diretta nell'uso, Ë presente la funzione trova file (find file) del menu File; parametri disponibili: file per la ricerca, contenuto dei file, punto di partenza. Midnight Commander si puÚ richiedere con mc oppure gmc su X-Window con GNOME.
- kfind
Home page: Requisiti: X-Window, KDE Dedicato alla ricerca. In pi˘ del precedente offre una scheda con dei parametri per delimitazioni temporali. PuÚ salvare i risultati in formato testo.
- tkdesk
Home page: Requisiti: X-Window, Tcl/Tk Rinomato gestore di file, la funzione di ricerca presente Ë ancora pi˘ completa dei programmi precedenti.
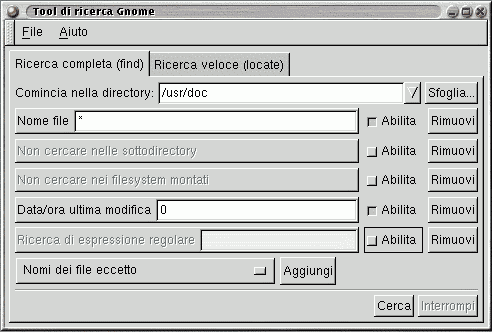
- Gnome Search Tool
Home page: Requisiti: X-Window, GNOME Una applicazione dedicata alla ricerca. Permette di limitare la ricerca con infiniti parametri di diverso tipo. Via shell si richiede con gsearchtool.
- tkworld
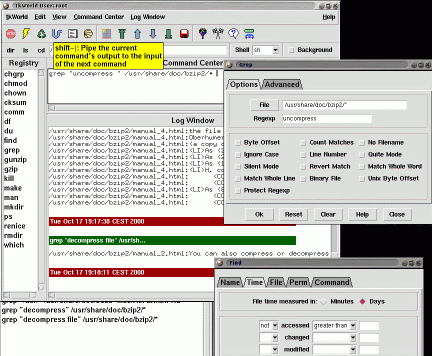
Home page: http://www.phys.ksu.edu/bailey/tkWorld.html Requisiti: Requisiti: X-Window, Tcl/Tk 8.0 Si tratta di un programma che intercede per mezzo di una interfaccia grafica ad alcuni tipici comandi Unix, i moduli find, grep e gli altri oltre a facilitarne l'utilizzano possono essere utili per apprendere l'uso di alcuni comandi comuni e il loro possibile coinvolgimento reciproco senza ricorrere all'intermediazione.
[note a margine. considerabili: rexgrep, kgrep, gtkfind]